Sky2Ground: Towards 3D Ground And Satellite Camera Localization
Zengyan Wang, Sirshapan Mitra, Rajat Modi, Grace Lim, Yogesh Rawat
@article{wang2026sky2ground,
title={Sky2Ground: A Benchmark for Site Modeling under Varying Altitude},
author={Wang, Zengyan and Mitra, Sirshapan and Modi, Rajat and Lim, Grace and Rawat, Yogesh},
journal={arXiv preprint arXiv:2603.13740},
year={2026}
}
Note: This post is meant to serve as an informal discussion for our recent CVPR 2026 work. Please refer to the paper and project page for more details. We gratefully acknowledge the support from our amazing sponsors at IARPA WRIVA program.
In this work, we perform 3D site modelling across ground/aerial/satellite viewpoints. First, we formalize this task for the broader community.
Localizing ground views in satellite images
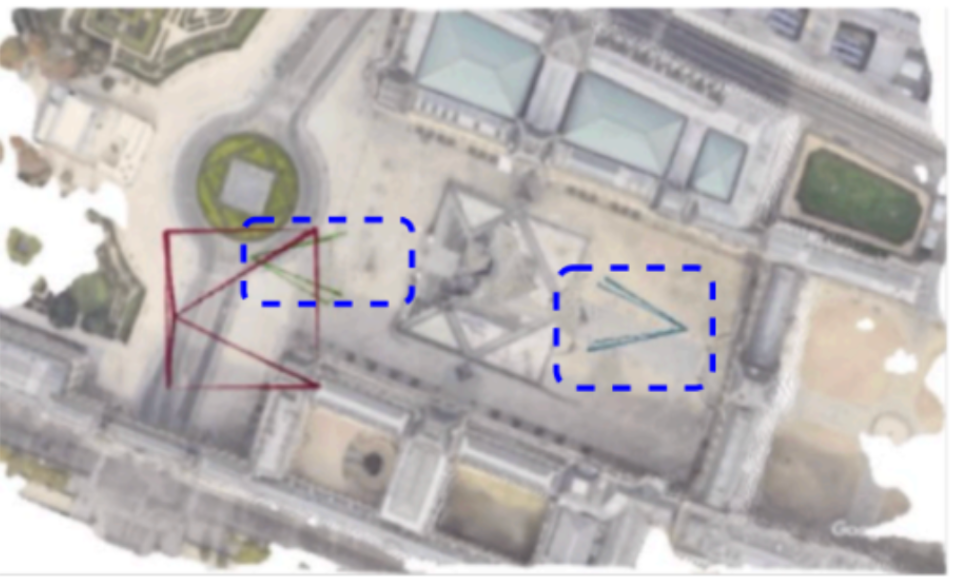
Imagine a three dimensional scene containing a pyramid, as shown above. We are given only three photos, namely, a red colored satellite image, and two blue coloured ground views.
The task at hand involves :
- Predicting the locations of cameras from which the ground images were captured.
- Constructing a 3D dimensional representation of the world (e.g., a sparse pointcloud or a dense render).
It is non-trivial to solve this task, due to following constraints:
- Ground views have no overlap: Consider, as before the two blue views, on `opposite' sides of pyramid. Given their limited field of view, there are no common pixels between them. Hence feature matching won't work.
- Symmetry Issue: The pyramid looks perceptually identical from both sides. This means that a neural network which predicts only one camera pose for a given image, won't be able to predict two separate poses.
We resolve this issue in the proposed problem statement, by including a third satellite view, as a result of which both ground views now lie in a common canonical frame.
The task then involves precisely poinpointing the ground views in a satellite image.
The curious case of VGGT
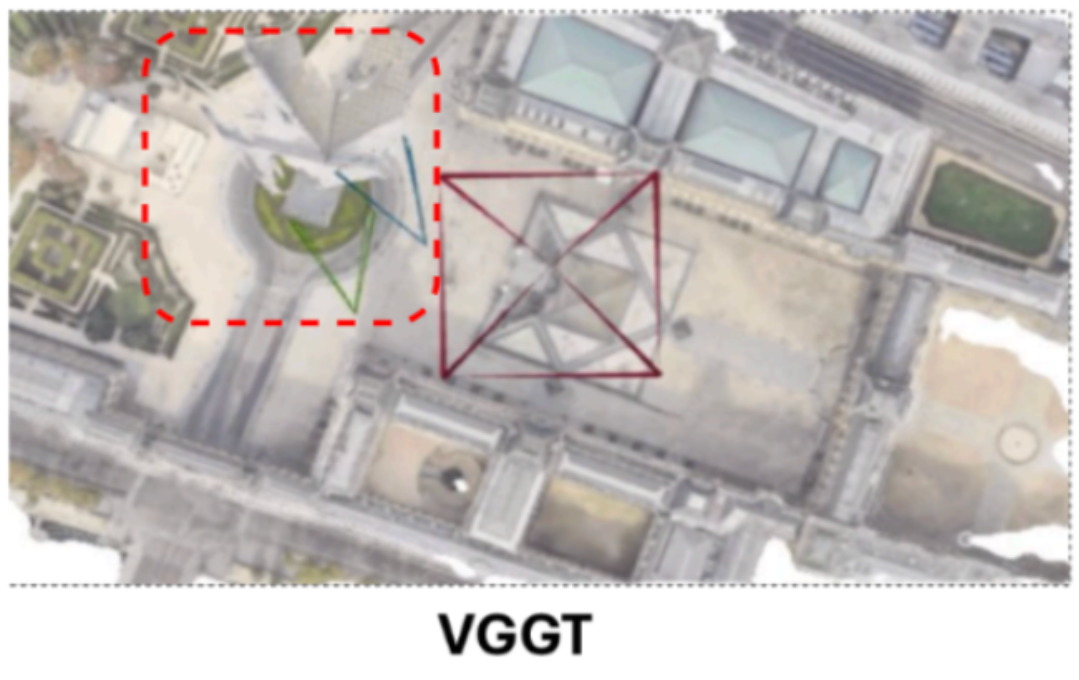
In figure above, consider how a SOTA model like VGGT performs on this task. We observe that it undergoes collapse: it predicts two ground views to be at almost same locations, even when given a satellite input.
Further, we find that the issue persists across 3D models which process pair of views together (for eg, Dust3r/Mast3r). This prompted us to investigate the matter further.
Are there any relevant datasets out there, on which we could conduct our experiments?
Existing datasets lag behind one of the dimensions
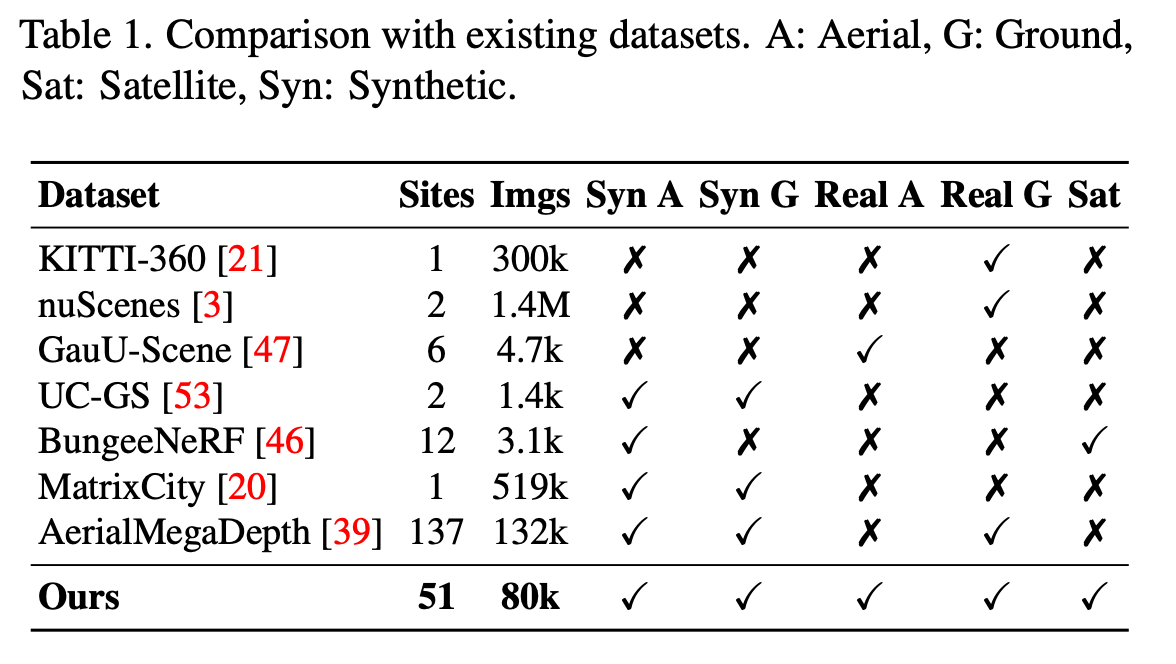
The table analyzes existing datasets, for eg, nuScenes / KITTI-360 are autonomous-driving datasets, and lack aerial/satellite views. Similarly, aerial-megadepth contains ground/aerial views, but lacks satellite-views. Next, synthetically- rendered datasets (using game-engines/unity3d) like Matrix- City, Bungee-Nerf remain limited to synthetic ground/aerial scenarios.
Thus, there is an urgent need for a dataset, which contains both real/synthetic images, across all the plausible viewpoints.
Sky2Ground Dataset

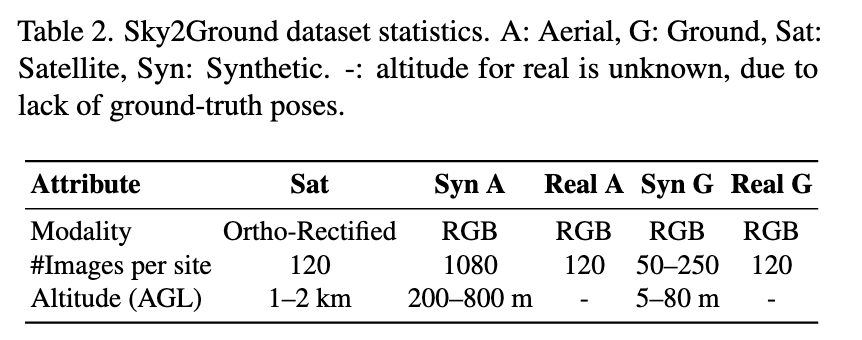
We present Sky2Ground, a tri-view dataset spanning aerial, ground, and satellite views, spanning both real/synthetic modalities. On average, our dataset contains 120 images per site, covering ~50 sites spanning across the globe. For example, consider the figure below.
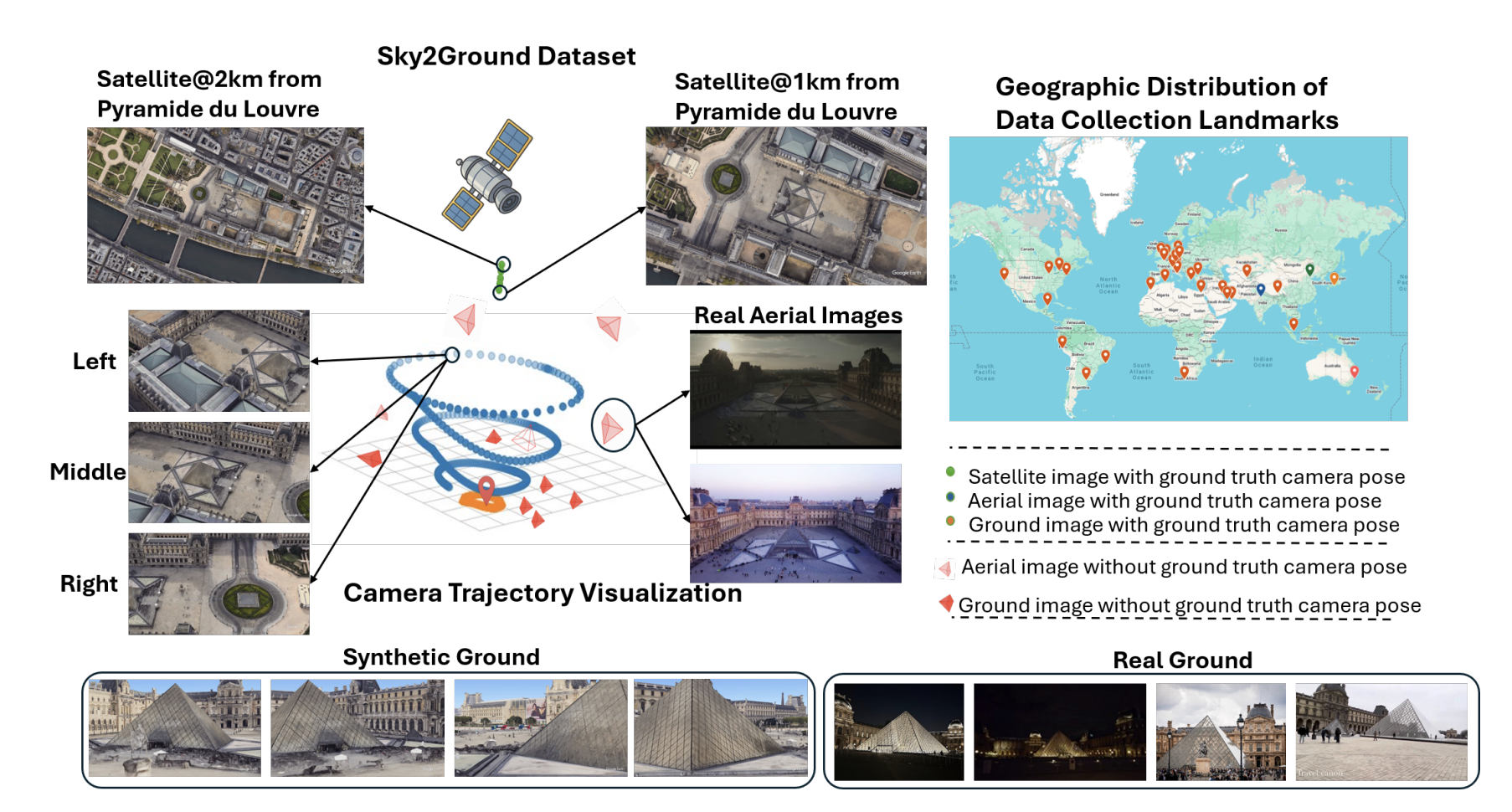
The plot on the right shows a geographical distribution of various sites in our dataset.
Specifically, we support two modes: (1) purely synthetic modelling (2) transferring synthetic to real imagery. For synthetic experiments, we render scenes via colmap, using annotations sampled from google earth studio. A qualitative example of such a scene is given below:

Similarly, we collect realistic satellite images (at very high zoom levels). For eg, in the figure below, first row corresponds to synthetic imagery, whereas second row corresponds to realistic imagery.
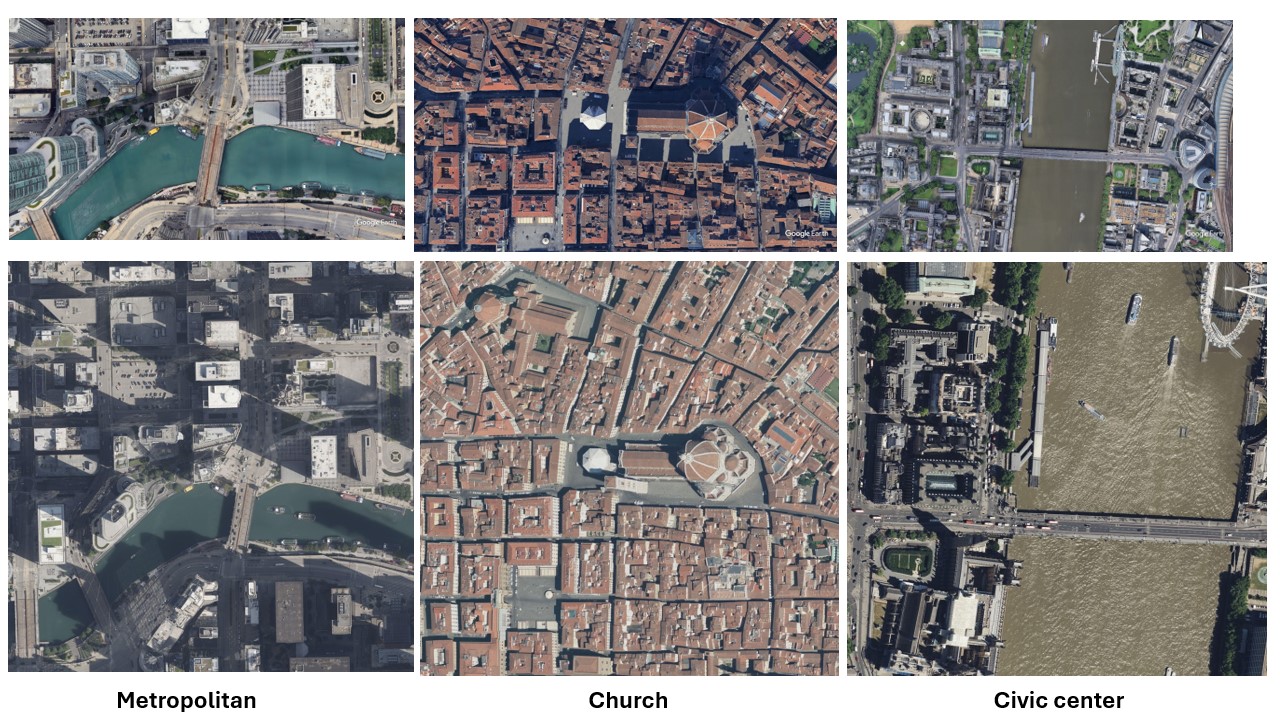
We have released the script to allow scraping more such realistic satellite images, for different geographical coordinates, on our github.
Enabling Analysis across varying levels of sparsity
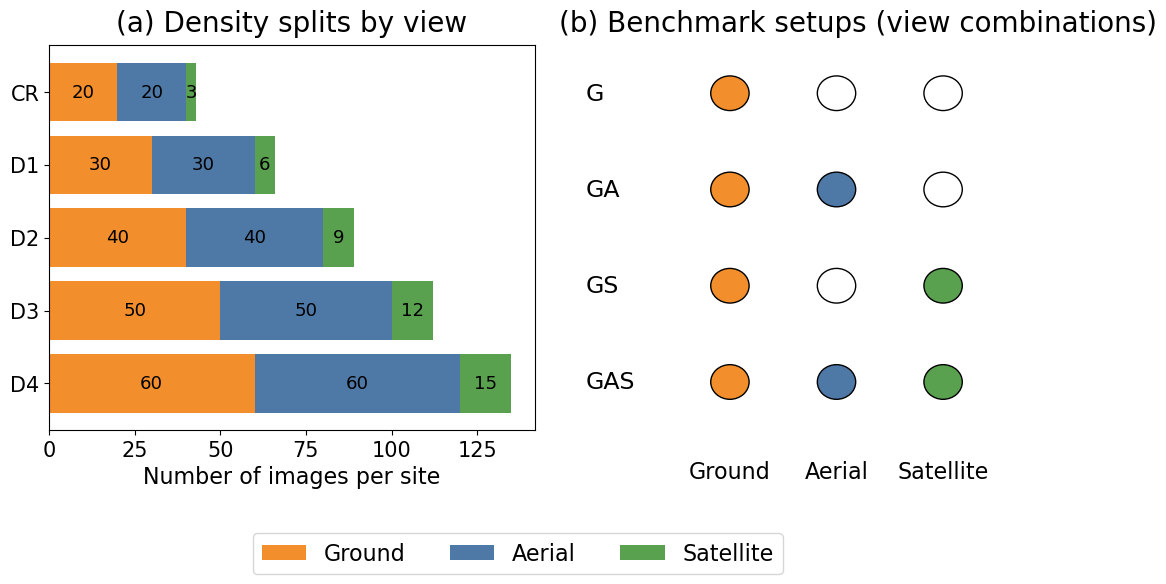
Our evaluation metric consists of different levels of `density’ ranging from D1, D2, D3, D4, with increasing density level (Eg, D4) containing more number of images than D1. Left part of the above figure illustrates different density levels.
For a particular density level, we provide different evaluation setup, for eg, GS: when only evaluated on ground+ satellite, GAS: when evaluated across ground+aerial+satellite imagery.
The Dust3r Demise
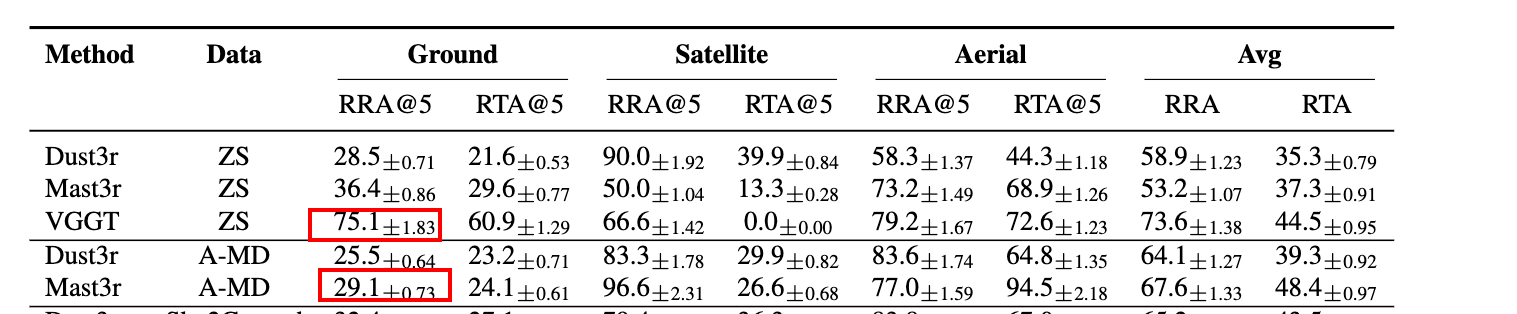
One of the key observations in our work is that existing models like Dust3r/Mast3r don’t work well. In fact, training them further on outdoor' imagery such as aerial mega-depth’ data results in performance drops.
Similarly, naively fine-tuning existing models with combined' ground/aerial/satellite data also does not work` well.
A surprising observation is that injecting as few as 1 satellite image causes huge performance drops. Similar observations like this were made in earlier works like Matrixcity paper.
This poses a need for a strong baseline upon which further progress could be made.
The SkyNet baseline
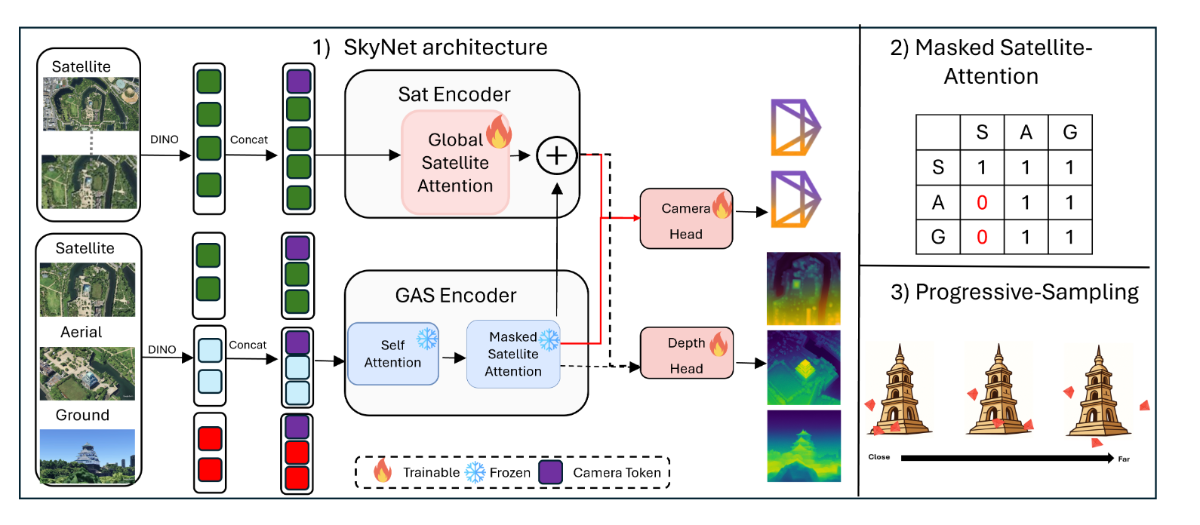
We propose SkyNet, an architecture that processes input data in two parallel-streams. SkyNet consists of two components 1) a ground-aerial-sat (GAS)-encoder 2) a sat- encoder.
GAS-Encoder: The Ground-Aerial-Satellite (GAS- encoder) consists of L blocks. In each block, all input views first undergo a self-attention. Next, we perform restricted- attention termed as Masked-Satellite-Attention (MSA). In MSA restricts ground/aerial views from interacting with sat. However, sat still interact with aerial/gnd views.
Sat-Encoder: Given multiple satellite images , we feed-forward them through a dino encoder. The output tokens first undergo a global-attention, where all the sat-views interact with each other, resulting in the latent z. Next, we update z = z + $v_s$, where $v_s$ are the refined sat features coming from the GAS-encoder.
We introduce two training strategies:
Curriculum Aware Camera sampling: During initial epochs, we sample cameras that lie closer to one other. As training proceeds, we gradually sample cameras far away from one another, for eg, non-overlapping cameras.
Progressive View Sampling : Intuitively, ground/sat views are extreme-viewpoints. However, aerial-images can serve as a ‘bridge’ connecting these modalities together[39]. During training, we sample N total images, where $N = N_a + N_g + N_s$ images, $N_a, N_g , N_s$ being number of ground/aerial/sat images. In beginning of our training schedule, we sample more number of aerial-views (N_a ≈ N ). Towards the end, we only retain ground/satellite images (N_a ≈ 0). Therefore, SkyNet gradually transitions from an easier problem, (localizing ground/aerial/sat views) to harder scenarios (ground/sat only).
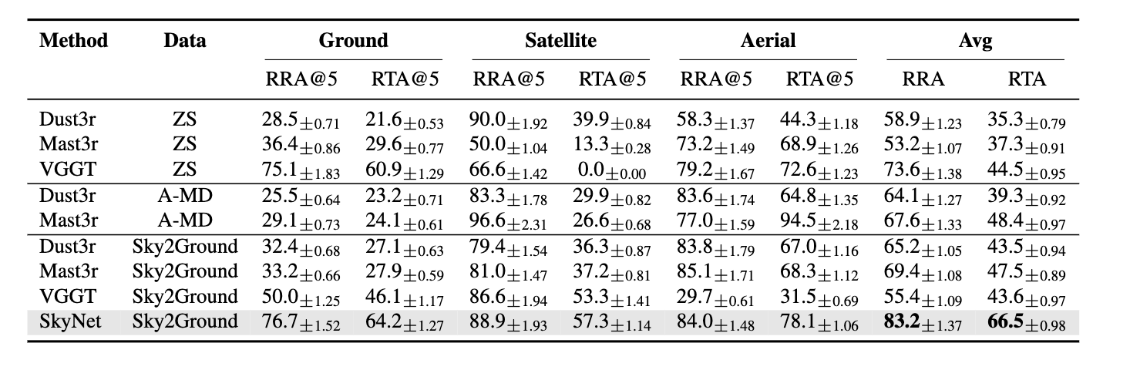
After all these changes, we set a baseline which is considerably stronger than existing methods, and humbly hope it drives further progress in our field.
Frequently Asked Questions (FAQ’s)
Here, we cover some questions, we have often been asked, in context of this research. By no means exhaustive, these are just meant as a subset of ongoing works.
Q1: What do the attention maps of SkyNet look like?

In figure above, we show the case when one satellite view, and one ground view are given to the network. The first row, chooses a query in ground view. We can see SkyNet’s attention map is very crisp (high red), indicating robust feature maps. Similarly, the second row illustrates opposite flow: when query point is chosen on satellite, we can localize the building.
Q2: How is this work different from geolocalization, geo-retrieval?
By definition, geo-localization is a 2 dimensional problem: one pinpoints (long, lat) of a given ground view in a satellite view. Similarly, there are various works which rely on a consistent Bird’s Eye View (BEV) representation: multiple ground view observations map to a common top-down observation.
Similarly, geo-retrieval, is a classification problem: given a satellite view, retrieve the most relevant ground images.
Our work is different, because a) it also can make use of aerial images, helping bridge the gap which comes from sudden viewpoint changes in satellite & ground images. b) we can predict “altitudes” of camera, as well predict yaw, pitch, roll of captured images. This 3D modelling helps the model learn better representations, than what simple 2D correspondance based learning can achieve.
Q3: What are the next steps?
We believe that this problem is far from being solved. Some interesting directions include:
- How to model the motion of objects, for eg, if cars/pedestrians etc are moving in the ground views? In this case, how can we break the scene into static/dynamic components
- Streaming scenarios: How can 3D models be constructed given observations arriving in real-time as a stream. How can one do long-horizon modelling, without running into OOM issues.
- Build better feature matches: Default colmap does not work quite well. Exploring alternative feature matches like superglue, etc, could be interesting.
- Iterative pose refinement: One failure case is that the network sometimes localizes cameras, but splits the pointcloud in two (or more) separate regions. `Merging' these into a consistent 3D representation may be of interest. For eg, one could rely on feeding a sequence of correctly registered poses + incorrect poses, feed-forward them into networks like Map-Anything, and try to iteratively refine them. A mechanism to calibrate which views the network "thinks" are wrongly localized may be interesting.
- Rendering Aerial images given only Ground Images: Given only a few ground images, how can one construct a reliable top-down satellite /aerial view. This task is particularly interesting, because it requires the network to have a sense of "mental imagery"
- Constructing a 3D dimensional representation of the world (e.g., a sparse pointcloud or a dense render).
Q4: OMG, your paper is OG, how do i cite it ? 🤗
Q5: OMG, your paper is cool, but i don't like it, how do i cite it? 🙃
We thank you for your interest. Indeed, research is a collective endeavour, and we just tried to take a first step towards this problem. Please cite us as:
@article{wang2026sky2ground,
title={Sky2Ground: A Benchmark for Site Modeling under Varying Altitude},
author={Wang, Zengyan and Mitra, Sirshapan and Modi, Rajat and Lim, Grace and Rawat, Yogesh},
journal={arXiv preprint arXiv:2603.13740},
year={2026}
}