Towards Making GLOM work: Asynchronous Perception Machine
Disclaimer: Apologies for the Academic Shitposting. I needed some place to vent.
Update 1 (Common Room of Starship Connectionist Enterprise): Some school-kid banter 🎉🎊🎆.
APM is one of the first steps towards getting Geoffrey Hinton’s GLOM working. The golden goose is how to encode part-whole hierarchies in a neural net. This goose has now started to have some feathers and lay some golden-eggs. This work was accepted to NeurIPS2024. Paper can be found here. And all it took was a MLP. There you go GLOM-doubters. Hiyaaaaaaa!!!!!!



Dr. Geoff Hinton wrote the GLOM paper. GLOM means “coming together”. And since it somewhat works now, So, on the behalf of everyone.
(footnote: German needs H)
And N(H)OW ,
as even the ST(H)ARS spanning the coshmosh,
shall be FORCED to bear WITN-(H)-ESS this grandiose-moment,
under the sacred laws of academic-tradition spanning MILLENNIA,
and the blessings of esteemed NeurIPS program committee,
(Me)mbers of the (ML)-Collective on this twenty eighth day of the month of october,
in the year 2024 of our humble lord JESUS CHRIST,
hereby,
LAY CL(H)AIM to,
Yannic Kilcher’s ,
“(Me)-GLO-(MiL)-lennia”.
Member’s locations can include any land, water, spaceships,
and inside volcanoes too. May this clhaim for(h)ever rest ,
ETERNAL,
UNWAVERED,
UNDILUTE
(a little cough…. D. sorry, ran out of breath, what was we saying? oh, we remember now)

May this claim forever rest ,
UNCHALLENGED,
B(h)y Jürgen Schmid-(h)-uber/s.
(so sorry, Hic!, Hic!,we are getting hiccups..)
Ok fineeeee, we are not so rigid. We will allow challenges,
By the po(ho)wer vested into MLCollective by,
Hinton’s Infinity Stones,
May this claim IF CHALLENGED,
Be resolved,
By the members themselves.
p.s. We have the supreme controllers, lords of the rings, from (H)-Uber/s too
(cc Rosanne Liu, Jason Yosinski).)..


——————————————————————————————————————————————————
Update 2 (sulking in control room): Hinton is hangry. He wants GLOM’s philosophy built into a machine. Quickly. Nooglers are worried. He just won’t take no for an answer. There is serious business to take care of.
My lovely PhD advisor Dr. Yogesh is a very strict, punctual and professional man. Every week, he wakes up early in the morning and makes me sit in his office. And then he glares at me from his ivory-spectacles trying to be all serious. I stare at the carpet and bite my lips. It’s tough, but I have to remind myself constantly: “Not again rajat. Please don’t laugh. Otherwise, he will get angry. Keep my mouth shut and listen.”.
We don’t want him to be angry. Took me two years to learn this simple lesson. Gosh, I wished I had learnt it sooner.
“Rajat, grow up. You are working on Hinton’s GLOM. GLOM= Geoff’s Last Original Model. Shift all this non-technical stuff to your blog post. Be professional. How many times do I have to tell you? As always, you keep complaining and never listen. I am really worried about your research” says Dr Yogesh, as he `suits up’ for his class. I can’t help it, but he reminds me of barney in “How i met your mother” .
You know what? he really takes all this stuff seriously. A lot of people are excited for computer vision after all. From outside, he is such a cutie-pie and an amazing teacher on whom a lot of girls crush over. Behind the scenes, he is a big godzilla who frequently unleashes his wrath upon little godzillas like me. Poor little godzillas.
As I gather my wits by what just happened, he swivels on his chair. Wheeeee. His desk is 45 degrees away from where I am s(h)itting, but within a constant slapping radius. Openreview is open on his screen for his review. He clicks a button and sends someone’s paper back to where it came from. Shooooo.
Omg. That really hurts. He is correct, so it hurts even more. And no-one can help me. Who cares about a poor, underfed, and miserable graduate student? Everyone has their battles to fight, hills to climb, grants to write, phds to defend and tenures to track. It seems I have no choice, but to finally listen to him.
So here we are. On this blogpost. You and me. Safe. Pinky swear.
And so I will tell you about this story of a new model called “Asynchronous Perception Machine”.
Now, ill be upfront and honest: i dont have a grandiose story to tell. There is no eureka moment: Unlike the much cooler Ian goodfellow, i didnt go to a bar or code up APM in a single night. This is a 3 year long journey. And it has just begun. I don’t know where it will take us, but if you choose to accept the mission (star trek), we will travel this bandwagon together.
So the whole story began when Geoff Hinton put out two papers on arxiv. He thought people had become too boring, so why not bring some excitement to the table. This is not his first time hunting, he did it with backprop, alexnet too. It seems that he exhibits a seasonal-pattern of sorts: he resurfaces every decade or so and whips up a rollercoaster. And when geoff Hinton speaks, we pause whatever we are doing and listen. Because, we want to stay on cutting edge of things and not become extinct like dinosaurs lol.
So, the first one of his rollercoaster was GLOM, and second one was forward-forward. GLOM was an idea which was not working at all, and forward-forward was a learning algorithm only working well on a dataset of black and white digits. I talked to quite a few people over the years about this, and they told me:“Hinton’s a crazy old nut”. That was a big blow to us part-whole nerds and their underground clubs. (Shame Shame, Poppy shame!! None of the donkeys will know your name!! I am a professional, even if they are not.)
In the perception community, there has been a long term cold-war going on. The clan-warriors can be split among two factions:
1) The connectionists, aka the SUPER COOL Hinton crowd: guys who believe that brain contains these little neurons. So in a machine, just build some mathematical equivalent of these neurons, and learn the connection strengths between them. Suppose a neural net has to represent an object. Then the presence of an object is governed by some distributed representation that it triggers inside the network. They invented the backpropagation as their weapon: that neural nets with multiple layers could learn interesting internal representations, and overcome the limitations of frank-rosenblatt’s perceptron. Frank’s perceptron was just a single input layer, and single output layer, and didnt possess any hidden layers. Sad perceptron. But anyways, backpropogation seemed to do the job well. It also effectively shut those people who boooed connectionism.
Now, we shall throw in some of our thoughts: which we spent several years thinking upon. They may be wrong. They may be right. We dont know. But, they do deserve a place. Let that place be this blog, because no-one seems to appreciate ideas, without working implementation that is. We saw earlier papers in 80’s getting in without results, but it seems that the trend has changed: research is ‘more sophisticated and empirical’.
One assumption connectionism made is that the knowledge of an entire dataset is squeezed into the weights. Basically, there is one set of ‘static-weights’ which is said to encode the knowledge of an entire dataset. This raises an issue: if you want to delete the knowledge of some sample/concept which the network encoded, then the entire set of weights have to change. A slight fluctuation in the weight space, distorts all the samples. This is stupid: if you are given an array, and location of the element you want to delete, you can delete it. Rest of the elements remain intact. An array is just a serial memory. A neural network is just a parallel distributed memory. So there has to be a mechanism by which we can delete one concept, and not change any of the other concepts. And that shall lead us to unlearning (hopefully). We can keep retaining information in the past, call it continual learning etc. But, there has gotta be a fundamental fix :-).
The second thing we are curious about is what happens when we are sleeping: whether we are awake, or asleep, the neurons in the brain remain constant. So our brain is a neural network. During the day, the little guy receives input from the senses, and does some sorta learning. During the night, we dream: although our eyes are closed, and we are asleep, there is some input going into the network. But, there is no input coming in from the environment. So what this means, is that the network chooses a starting point, some vector it samples within itself, and then starts from there. The third thing is something i call dynamic states. When we sleep, the patterns in the brain keep changing. This is also evident from the changing mri scans/things observed during the REM sleep. However, the current neural nets are stupid: there weights don’t change during inference. Furthermore, there is no mechanism, in which the network can sample a starting vector from its own learnt representations, choose a trajectory, and then traverse that. Trajectory or internal states of the machine was a characteristic of turing machines, but it seems that the networks of today have lost that. Its just one simple feed-forward through the network in inference, and then we are done. That makes no sense. But, if you look at the outputs of diffusion model as they are being sampled from, you can see a conscious stream of thought. You may say it’s not thought: a mere sampling, the argument is up for debate. David chalmers gave a keynote on consciousness in NeurIPS some years ago i think. And we will hedge our bets on: they are thinking. You are free to choose whatever you believe in. It’s a democracy after all.
This means that there are two phases of learning. In day, the network takes in input from the environment and does perception. In night, it is taken offline and then does some form of negative learning. Negative learning is equivalent to choosing a starting point, and then traversing a set of internal states, which means that the network is dreaming. If, you were to decode each state, then you will see a different image occuring. This is similar to our dreams: they follow a conscious path. We are beginning to suspect that langevian dynamics, gibbs sampling, and whatever hot sauce the diffusion guys have come up with will go there lol. Don’t worry, we will just steal it and apply it to GLOM :-).
Now, let us talk about boltzmann machines a little bit ehh. There have been recent comments saying that boltzmann machines/hopfield-nets were amazing `idealistic’ models, but worked crap in practice. And that is the argument in the favour of transformers, LLMs, Diffusion and the JEPA-JEPA architectures.
We will instead present a counter point. Again, we may be wrong. We accept that.
Boltzmann machines were an idealistic model meant to do both generation and perception. Perception in day, and generation in night akin to dreaming. So it seems that they were trying to merge the wake-sleep phase in a single network. Next, we come to the matters of traning the boltzmann machine. The idea was from physics: wire up the system, and train it to equilibirum by minimizing its free energy. Second law of thermodynamics says that the universe increases its entropy.Training neural nets relies on decreasing entropy. Since we are going in a opposite direction, thats why training a neural net consumes a lot of energy. Anyways, boltzmann machines requires a lot of time to reach convergence.
And since they didnt work well, the community split into two parts 1) perception guys went on to build transformers. 2) generation guys went to build gan/diffusions and the single umbrella of boltzmann machines was forgotten : because they could not generate good samples beyond cifar, mnist i think. Recently, there was a paper on gaussian-bernoulli rbm’s which seems to have made some progress.
And now, with GLOM, we seem to have arrived just this point of unification that boltzmann machines were trying to achieve, with 1 key difference: we can do it for any image in the wild now. So, we can do perception. But not as well as a transformer. We can do generation. But not as well as diffusion. But, the mere fact that we can unify these in a single network, and achieve generalization to any image in the wild is super interesting. This suggests that this is now a direction worth exploring. Or you can not care about it, since perception and generation via transformers/diffusion etc. is already SOTA. Again, your choice. Keep chasing SOTA. It’s a democracy :-).
2) The symbolists, i.e. the minsky crowd. They believe that there are symbols in the brain, like some representation of what an apple means like, what godzilla means like etc. So brain has all this interesting grammar for all these objects. This vocabulary is called symbols. Then these symbols interact with each other at lower levels, and some reasoning happens at the higher level.
We are sorry, but we haven’t studied much of symbolism. So we will skip that school of thought for now.
There has been a great deal of bloodshed on both sides. Countless soldiers have sacrificed their lives to their respective causes. There is no clear winner. People have lost hope. There is no settling this debate hmmmm.
But now we are in the times of peace and love and an occasional tease . So, we need an interesting compromise. A peace treaty of sorts. Something everyone could be happy with. GLOM seems to offer just that. The only problem was that it was a mere philosophy.
The difference between science and philosophy is that experiments can show that extremely plausible ideas are just wrong and extremely implausible ones, like learning a entire complicated system by end-to-end gradient decent, are just right.- Geoff Hinton, GLOM
Stupid ideas work, and everyone seems happy with them. After all publishing is an optimization problem right?: Maximize the number of tier 1 papers in shortest time and in least amount of investment. Who cares about quality and fundamentals, as long as the citation count is high? GLOM is intuitive, but was not working in practice. With APM, we try to rectify this problem and argue that what is in fact intuitive, can actually work better in practice.
So, what is GLOM about, and how does it settle the debate between the warrior factions of connectionism and symbolism? For that we take a look at Hinton’s glom paper.

It talks about a new representation called islands of agreement, and a way to use these islands to somehow do machine perception. But, before we define what are islands, what are these little arrows, we will label his figure a little bit. Trust me, it’s a revolutionary idea.
Let’s say you are given an image of mona-sparrow. Something like this:

And you then chop mona-sparrow into pieces and label those pieces as 1,2,3,4. So basically, each of this piece is a token you feed to the Hinton’s glom. This is how you feed it from the bottom:

Now we will start introducing some technical terms shall we. You will notice that the figure above has 6 columns. There are 4 tokens, and last two are trash cans. So basically, we only need to look at the leftmost 4 columns. Now, consider the token marked 1. Look at the column sitting on it. That column has 4 arrows and a question mark on it. What are all these arrows? The idea is that this column consists of 5 levels, at lowest level it might be representing the nose of the mona, and at the second highest level, it may be representing the entire mona lisa object. Therefore, the lowest level is representing a part and the second highest level is representing the object.
Now, you will see there are a bunch of arrows. For eg, consider the three red arrows. Perhaps all those red arrows are representing the mona sparrows face. Now look at the lowst level, those black arrows. Those might be just rgb pixels, and scattered together. The red arrows are in three of the boxes, and they are pointing in all the same directions. Same directions mean that they are all “agreeing” that it is mona sparrows face at that location. Therefore, this leads us to the following conclusion:
As we go up in the GLOM’s levels, the amount of agreement increases. There are more number of red arrows at the second highest level which agree with each other, than the black arrows at the lowest level.
Next, you will notice that i marked the last level as useless shit. Why did we do that?
Here is the argument: the original idea in GLOM was that at the highest level of the GLOM there is a single representation, which represents the scene level information. So if you took images, say mona sparrow at your home, and mona sparrow in your school, the network will be able to understand the difference between the home and school. But, in practice, it seems very difficult to converge on a scene representation. This is also the reason why the research between the computer graphics community (aka those neural fields) and perception community is split. The rendering community just focuses on rendering: how to model radiance fields. Their representation just keeps changing with the viewpoint. On the other hand, the perception community does not give a shit about radiance fields: they only model first four levels of glom, i.e. the object level. Not the last one.
Now, we shall talk about another concept called The information bottleneck principle. If you look at the figure, you will see there are equal number of arrows at each level (i.e. 6 arrows per level). This means that when information (aka mona sparrow) tokens are fed into the network, they travel through allll these levels and somehow result in these arrows. The number of arrows does not change across levels (there are 6 arrows per level in Hintons figure lol), so there is no loss of information. There is no downsampling like the one which occurs in CNNs.
The next insight in APM is as follows: Each of the levels of the GLOM system corresponds to a different layer of the VIT, aka transformer . This assumption works in practice, because in the transformer there is no bottleneck problem: there is no upsampling or downsampling of the input tokens. That remains faithful to the figure that Hinton drew. Lolzy. We have marked that L layers of a transformer (VIT) on the Y axis in glom’s figure.
Ok, so now we need to learn all these arrows. Sometimes they are all red, sometimes they are black, and sometimes blue lol. So, how to learn them. Well, the answer is very simple. Don’t learn them lol . They are already present in a transformer like Dinov2. Here is a figure that i stole from Shir Amir’s paper yo:

So if you look along the arrow i show, it shows that as you progress along the different layers of a DINOv2, the representations are pretty cool. At the last layer, all the representations of the DOG like ears, eyes, mouth have automatically given themselves some color. Note that this network was NOT trained with any class labels, just a simple self-supervised loss lol. So this told us that there was something interesting going on in the transformer, and it was able to automatically learn the object parts and their wholes. Somehow, we needed to exploit it.
Like a cutie pie we are, we were parsing through Hintons forward forward paper. And then, we came across this line:
A static image is a rather boring video - Dr. Geoff Hinton, Forward forward some preliminary investigations.
And when geoff Hinton says something, we do that. seriously, just do that. its that simple.
So what did we do? We took a static image. We repeated it many times along through a temporal axis. Then it became a boring video that does not move. And then we gave this boring video to a video-transformer like Mvitv2. Note that this Mvitv2 was trained only for action-recognition, and no semantic information was being used here. So, we took a video and pumped through this transformer. We looked at the second or third layer of it, and selected the higher dimensional tokens corresponding to a particular frame. And then, a cutie pie told us to do three dimensional t-sne clustering on them. And so we did that lol. And this is what we get:
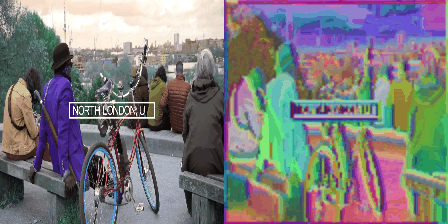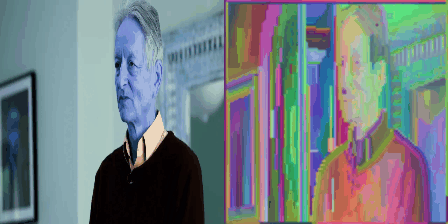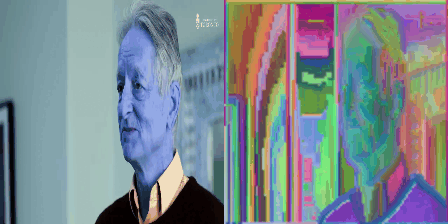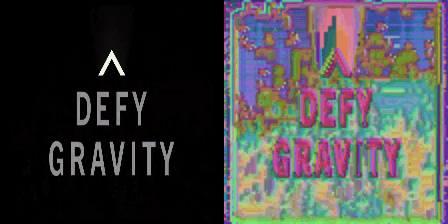
So basically this showed that even lower layer in the transformer could give us such sexy islands. And they were soooo beautiful. And these islands were one of the levels in the GLOM. And if we got these islands from different layers in the transformer, they would serve as free sources of supervision for GLOM. So basically, it would tell each layer of GLOM what arrows are what lol. We dont need to learn them. They are already there. So we will just distill representation from a transformer like Mvitv2 or Dino in GLOM lol.
Now we wish to redirect your attention to one thing. Notice that the islands in the above figure were obtained after repeating a static image along temporal axis to become a boring video. This is very subtle trick: To converge on a stable representation for a scene (in this case a static image), there are two ways you could go about it. The first way is to look at the same image recurrently over many iterations. That will make the network know what is the best representation of this image. This is what GLOM said in its original paper. It said take a image and do many routing-iterations on it. But, we don’t wanna do that. Instead, we do opposite thing. That is the second way. When we repeat the image along the temporal axis, the network looks at the multiple copies of the same image in parallel lolzy. This operation occupies more memory but takes less time than having to do routing in GLOM. And it gives beautiful islands.
So all the above discussion can be now wrapped up in the following simplified figure:

Now is the time to visualize this whole thing. Trust me you cannot understand it otherwise.
So, in the above figure, the trash can means that the input sequence is padded. So, we will be not concerned with any of the red marked region. We already know that the good source of supervision for all the remaining locations in the GLOM can come from a teacher. So let us imagine a teacher. And it can hop around the different locations in the Hintons diagram and tell the GLOM model which arrow belongs to what location. This transfer of arrow (aka island) from the teacher to the GLOM is called ZAPPPPP!!
But, there is one last thing in the GLOM diagram that we need to get rid of. Notice the GLOM’s figure along the columns. There are four columns (each containing 4 arrows and a question mark in itself. ) In the original GLOM formulation, these columns were communicating among themselves, and telling each other what arrow goes where. But, in our case since the teacher is telling that information to each cell of GLOM, there is no need for having these columns to communicate among themselves. No more routing lol. No routing, no attention. No attention, no memory issue. It’s that simple. Hiyaaaaaaaaaa!!!
But it really is not simple. If the columns dont communicate, how does the GLOM know that it is looking at left half of mona-sparrow, or right-half of her. Afterall, machine perception needs all patches to communicate amongst themselves? And that is the idea of attention right? And using attention means using too much memory. We dont want to do this. So, we will do this another way. The above diagram can be changed as follows:

So each column of the GLOM is carrying the whole image in it. Since it contains all the image in itself, there is no more need of attention. The input already carries the context with it. No more routing between columns. That will save memory. Different columns can be numbered according to 1,2,3,4 etc. That way, by concatenating the global image (I, p), where p is the positional encoding, we can create a strong enough column representation for any location. So, the GLOM’s architecture will now take this column representation as input and solve the following problem:
Given the entire image as input, and a location in the Hintons diagram, what is the arrow at that location. That answer can be given by a transformer as a free source of supervision and in this way GLOM can be trained.
So we now know that teacher is a transformer. The only problem left is what does the architecture of GLOM look like lol. And to put it together with the teacher and train the little boy. So the GLOM architecture now somewhat like this:

We have a mona sparrow image. THen suppose we consider a single Column 1. The column contains entire mona sparrow, and positional encoding corresponding to 1. And then we give this column to MLP. And it screams an answer. That answer is wrong. The teacher zaps it. And MLP does several iterations on this column and then gives the correct answer. The process is repeated for all such dotted columns.
We will look at the design of this column.

So this column contains a single cnn filter. We take mona sparrow and run cnn filter on it. That writes these patches to the column. And we can then generate a hardcoded encoding like 1, 2, 3, 4, attach it to column and in this way create a location-specific query for our little MLP. The learnable parameters of this whole little network are just in one CNN filter and one MLP. That’s all. Thku so much transformer. We kept your positional encoding. Positional encoding is what we need. Hiyaaa!!!!!
And the way it should pacify symbolists is like this: CNN filter can be thought of as a device which writes symbols on the column. The MLP is akin to a turing machine which reads those symbols and processes information. The output of MLP is vectors. Reasoning is done by operating on vectors in the higher dimensional space, much aking to Word2Vec paper by Mikolov. The only difference is that mikolovs paper did that for words, and talked about analogies in the higher dimensional space. In APM/GLOM the vectors are for images now.
And here is the final architecture for this cute-little model called Asynchronous Perception Machine. Little godzilla still keeps gazing at the simplicity of it.


There are still a lot more papers to be shipped to NeurIPS for babies. 👶👶👶👶👶
As turing concludes in his seminal paper, “We can see but a short distance ahead, but we can see plenty there that needs to be done”. This is a call to action. Please join the ship before it is too late. In any case, this ship is being driven by at least one small mortal machine, for as long as he is on this planet called earth.
till next time,
love,
little_godzilla/s
——————————————————————————————————————————————————
Update 3 (sleeping quarters): Hinton and Hopfield get nobel. Roommate woke me from sleep early morning. The shock of nobel prize is still sunking into MLCollective. Congratulations are flowing around. Everyone feels it’s their nobel. AI is the new physics lol.
On this lovely rare-occasion, as Nobel prizes are being doled out to AI, which (according to some people) is NOT a fundamental science or a mere application of physics, we have curated a special series of little godzillas just for you. Each one of them took a lot of time, love, and effort to make. We shall now study these godzillas one by one:

This is a godzilla with a crown. He is used when he is doing well on some benchmarks. But most of the days, he looks like this when the experiments fail:

But there is no smile on his face, because he is sad that experiments didnt work.
On an occasional weekend, things get too intense. Godzilla has to get out of the lab. His roommate has been very kind to take him to places, because godzilla does not know how to drive. Afterall, Godzilla is not invincible: there are things he cannot do alone. In return, Godzilla buys his roomate food. Food for the car’s gas is the deal. Roommate happy, godzilla happy. Their wallet is happy. Win Win.
Godzilla’s roommate is called a soumik-ghosh. He comes from west of bengal, a bengal tiger you know. But roomate always angry. He wants to be called S-(how)-mik instead of S-oumik. Godzilla has no idea why people dont keep their names like they want it to be pronounced. But angry roommate means, no car. So godzilla careful.

Sometimes, Godzilla has to read papers on the arxiv. But, he has poor eyesight. So, he resorts to wearing spectacles. Contact lenses dry up too fast. He gets long hair before paper deadlines, and godzilla even forgets to comb them. He gets all sweaty and smelly in those tough times. You really don’t wanna annoy this version of him. This godzilla also looks like my friend Sarinda, although it’s a matter of debate: Sarinda has long maroon hair and he says that this godzilla’s hair are red. I don’t agree. Maybe i am colour blind too lol.
p.s. shneaked in a little godzilla in our paper. sooo shorrry. Please don’t tell my advisor. He’ll be angry. We don’t want him to be angry. Angry bad. Happy good. Mooooooo…………. Ok, you can tell him, but after i graduate. Not that he can do anything much. Neurips camera ready deadline has already passed lol. Hiyaaaaaaa!!!!!!
Future work
In future, we plan to make more humble godzillas. Each godzilla comes with its own outfit and ablation experiments. You can tell us which ablations you like, and we will combine those to form a nicely-dressed godzilla that remains competitive. One that is customized just for you. And we will do it for free. Without a GPU that is.
Limitation
Godzilla-making-addiction. Little godzilla is a mere mortal after all. Sometimes, godzilla is rejected from CVPR/ECCV because he cannot surpass SOTA. Little godzilla is also not that robust: he should be tested extensively in the real world. And for now, poor godzilla only does image-classification. That’s not a “real” computer vision task. Godzilla needs to do dense tasks, reasoning and alignment also. And dont even get us started on the hard problem of consciousness. Is it really hard? Alas, only time will tell lol.
References

“Hinton. Geoff Hinton. The Godfather. How to represent part whole hierarchies in neural nets”.
What’s next after nobel and turing😂? Fields Medal? Gotta catch them all. Perhaps, I dont need math, because maybe i can learn it with backprop. Or maybe Mars should be next. Really, I’m super serious this time. It’s tough to decide.
There are some rare instances when even NeurIPS panels don’t understand what little godzillas are saying. But you cant blame little godzillas, they are still small and have a lot to learn. They dont even have a masters degree yet. For eg, you can play this video. This was Unireps workshop panel in NeurIPS 2023. Remember: go full screen, playback speed 0.25x and select the highest quality lol. Don’t forget to notice the super-cute smirk and pierced-nose-wrinkle between the timestamps 1.00- 1.06 :-).
Splendid!!! Pure gold ehh :-) Just in good-humour hehe. In his defence, Little Godzilla gets nervous easily. He is not that comfortable on big stages, you know. So he lost his shit and blabbed all over the panel. Shorry. Luckily there wasn’t enough audience to notice little godzilla’s nervous breakdown.
And now before i leave, and you go all awwww and shaaaad, i will dump a few videos we created for this project over the years. This jekyll blog is stupid and embedding these videos messes up the spacing. But that shouldnt prevent me from sharing cool stuff with you. Yes, you: the bigger godzilla. Little godzilla loves you. So here you go.
All little godzilla requests in return is protection from being schmidubered. Please protect him. Little godzilla is still small. Very small. Less than a GB of memory. Maybe little godzilla should go to big godzilla for protection and join his gang. Big godzilla has a nobel now, so he might be able to provide some mafia protection.
And before you start thinking that little godzilla is very creative, he isn’t. He just stole the idea of folding and unfolding from big godzilla. The last line of big godzilla’s paper talks about mental folding. Bulleted below. Hiyaaaa!!

Ok, here are the videos I promised:
It is late night now. We have been on this blog for sooo long. Little godzilla will now go brush and floss his teeth, gargle on crest’s mouthwash, put on his (k)night-suit and go to bed on time. Afterall, he becomes sick pulling those all-nighters. He will hear big godzilla’s lullaby on a laptop sitting on his tummy and tuck himself in. Especially the old coursera lectures. Hiyaaaaaaaaaaaa!!

Big godzilla’s lullaby in action. It helps little godzillas wake and then sleep again. Wake-sleep algorithm he he. Wait, the slide says Kevin Swersky. Alex Kryzhvysky. Swersky. Kryzhvysky. Kryzh-(vys)-ky. Kryzh-(swe(a)rs)-ky. Zzzzzzzz. There is a part-whole relationship there after all.
love,
little_dogzilla/s
——————————————————————————————————————————————————
Update 4 (Remote meeting with earth): Hinton has been pacified (for now at least), but advisor scolded me today 😢.
Gotta do something about this 😡.

Behold!! “The Silent Man” in Openreview and the NeurIPS community. May this silent man be cherished.
May, the silent man remind us of slow science. May he make us remember, that as the world goes in a state of turmoil, there are a lot of silent men standing guard. May the silent man remind us that science is greater than ourselves, and it is the collective progress that matters. May the silent man remind us that humanity is our collective relationships, love, and mutual respect for each other. May the silent man help us be humble and true to our families. May the silent man help us remember that we are still dependent on each other. Merry Christmas!!. May the silent man be the santa claus who brings hope and gifts in our lives.

Reflections of the silent man can be found here. Silent man is a mortal machine, which is imprecise, which then reduces to Geoffrey Hinton’s latest idea of mortal computation. A silent man. A true godzilla. A noble nobel-prize-godzilla. At least one generation of Nvidia GPUs ought to be called Hintons And Hinton Perception Machines (HPMs). But, who would listen to a poor underfed graduate student anyways ? The world goes on.
Geoff Hinton on mortal computation.
——————————————————————————————————————————————————
Update 5: Transmission from a wormhole🚢🗺️🔭
You can checkout the figure on page 27 of the APM paper :-)
There is another easter egg🥚 named barney. See if you can find him.
p.s. plz plz don’t tell NeurIPS and my advisor. They are strict. 😠👩🏫🪄. Shoooo!!!
——————————————————————————————————————————————————
WARNED.

Don't mess with it. Or you can. We don't mind.
The more, the merrier. Gotta catch them all.😘
——————————————————————————————————————————————————
Update 6: Advisor scolds me again.
Gotta do something about this 😡.

And yeah, this one is special.
It was bestowed by Hinton.
Really, we are sherioush.
You can ask him if you dont believe us.
The one you buy on amazon doesn't possess this kind of mojo.
And if you steal it, that mojo won't work.
It's custom built.
Correct-part needs to route to correct-whole
To have a correct-relationship.
It's that simple.
If you want your own dogzilla
ask Hinton. He's known to be generous.
If you can catch him in good mood.
He wiggles out pretty quickly. We tried for 3 years,
he continues to operate,
the cold-canadian shadows,
and the warm gmail-inbox of,
geoffrey.Hinton@gmail.com
Let’s make their gradient-descent/backpropogation/knowledge-distillation go away too 😛. nah, just kidding😉. promise🤝. pinky swear.
we’ll behave,
until i finish my machine learning midterm that is.
need masters.
mebbe phd one day.
i love my advisor, he allowed me play :-)
what will Hinton come up with next?
we are shoooo curious.
meanwhile, i will read some isaac asimov’s irobot and ray kurzwell.
and a sprinkle of francis crick.
——————————————————————————————————————————————————
Update 7: Advisor has scolded me agaaaain.
Something needs to be done about this.
one final action, and i’m done. promise.

And yeah, dogzilla's shameless by now.
Dogzilla has finally reached 4th year.
Dr. Yogesh cannot get rid of him anymore.
It makes him angry.
That's part of the fun.
Torture dogzilla for 2 years
Then dogzilla tortures him for eternity.
That's the DEAL. The Hinton will agree.
The right to torture has been earnt.
Dogzilla's posterior is pretty confident by now.
——————————————————————————————————————————————————
Update 8: The shock of receiving the reply to a nobel-dressed godzilla is still settling in:
I thought i was crazy, but never cared. Apparently, there are people crazier than me. Snippets after i blew my shit. Was in a cheap orlando apartment with a very costly internet when this happened.
The reason we are sharing this particular `personal’ message is that we have carried this burden long. They deserve to be finally out in the open. It is bigger than us. All credit goes to MLCollective. All other things are classified by the MLCollective.
So i sent the following to Geoff Hinton:

And wasnt expecting a reply. But we got a reply.

Hmm, So this writing style seems important,
For correct prose,
and charm,
It lets each line,
hit you, as you,
scroll down,
And that’s how i lost my shit (again!!). (in star trek/star wars) style.
A good scientist always cherishes paradoxes, and does not settle until he has turned the oyster back into a pearl. This line stayed with me, when Hinton addressed some students at IIT-Bombay. I did listen to the video, which seemed to have struck some deep chord.
In this whole journey, my advisor has been constantly with me. He allowed us to do this weird work when we gave up. He stood for us when noone else believed in the idea. This taught me what character means. Some things in life cannot be faked. Some things in life are beyond money, fame or prestige: which is a part-whole relationship b/w a phd student and their advisors.
Forever,
Members of the MLCollective.
zz
——————————————————————————————————————————————————
Update 9: The kind folks at MLCollective
The folks at MLCollective were kind enough to give us the privilege to present this work at the DLCT session. So we are dumping those slides here for your kind reference. If any issues arise, please do let me know at rajatmodi62@gmail.com
Slides:
NeurIPS poster: