Structure of mental imagery and the nature of shape representations in human brain
As scientists, we don’t yet possess such a divine eye. In fact, the human perception of things often gets impacted by cognitive biases. Our belief of what is the real truth, and what the actual truth is are a lot different. Unless, we try to quantify the randomness in our brains, we cannot devise the learning systems which model the real truth. What is it that humans see differently that a computer does not? Does the human visual cortex favour lower level processing or just learns from higher level concepts? Are there any particular representations that we favour? If so, what is their nature? How can a computer achieve this level of abstraction? These are the fundamental questions that trouble us.
In our last post, the scales had tipped in the favour of a set of neurons as a replacement for associative memory. Instead of relying on memory addressing, the fundamental unit of storage had become the strength of synaptic connections between the neurons. Each such pattern modelled a global representation which was obtained as contributions of relaxed local representations obeying a certain set of constraints. The outputs of such a system should match how a human perceives the world. To understand the nature of outputs a human favours, we can perform various psychological experiments on ourselves.
Anorthoscopic Perception
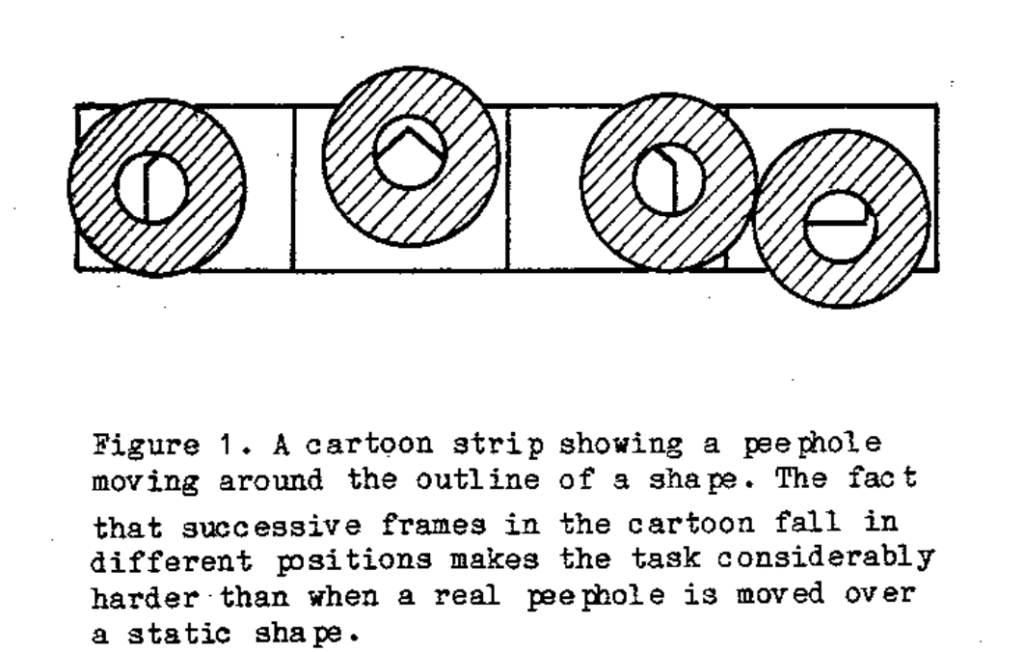
Imagine that a hexagon is kept on a table vertically and is viewed through a peephole. Consider the position of the peephole as constant and only one of the hexagonal side being exposed to the outside world. So what a viewer sees is an edge and the relationships with immediate neighbouring edges. For simplification, we are still going to say that the peephole is moving when in fact the object behind it is moving and advertising different parts of itself to the world at a time.
As the peephole traces the hexagonal edges over a sequence of frames , our brain ‘remembers’ what it has seen. After a certain time, we integrate the information we gather and arrive at the conclusion that it is a hexagon. Therefore, a cluster of neurons must possess a working memory which stores activation patterns of a series of external stimuli and outputs a decision after some lag.
Now suppose that instead of sliding over the ‘consecutive’ sides of the hexagon, the peephole starts to show the sides randomly to you. For eg, it might show side 1 and then side 4 instead of sides 2. Will you be able to still appreciate the fact that the shape is a hexagon? No. This means, that the human memory has an ‘attention span’. Multiple frames of hexagon sides are combined to form a ‘chunk’ of global representation (hexagon from edges). The condition is that the consecutive chunks should lie in the attention span of the human being. This helps us understand that along with a working spatial memory, a set of neurons needs to possess an attention span to arrive at global representations.
The Hinton “Uncertainty” Principle
So, we understood that brains possess the ability to create global shape representations from a time-series data of “patterns”. What about there ability to detect precise object positions in a three-dimensional environment. Turns out, not so much.
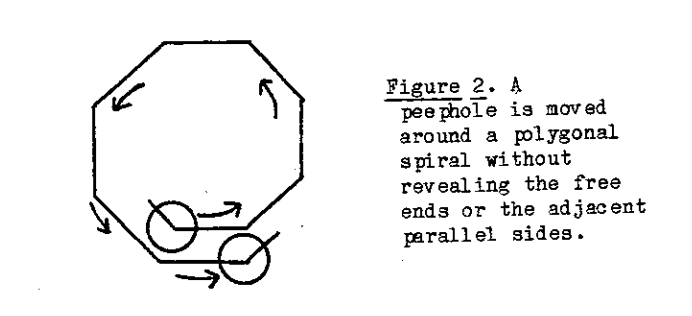
Take the same hexagonal setting with the peephole sliding on it’s boundary. However we have made a small change. The real shape of the polygon is no longer a ‘closed’ hexagon. Rather it is open at two ends. But, will a human detect this change in the ‘real polygon shape’ if only a part of the object is visible through a peephole during a single exposure? No. This leads us to conclude that humans possess an innate ability to represent shapes properly, but not the spatial coordinates.
Shape vs Position in Computing Devices
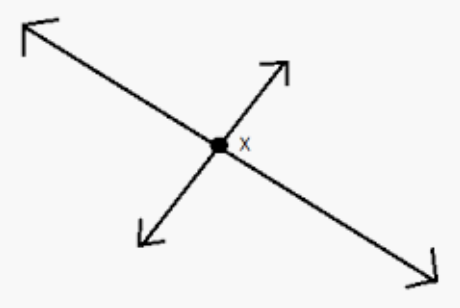
Imagine that a pair of intersecting lines is given. We ask a simple question to a computer:
How much straight these lines are (in length)? Do they Intersect?
As humans, we took one look at knew the answer that they intersect. But not their actual length’s (since our brains are bad with lengths). In case of a computer, it is opposite. A line segment is gonna be stored as a data structure with X and Y coordinates in an array. To calculate the length, it can calculate the euclidian ‘norm’ in O(1). But, to decide whether the lines intersect or not, the computer has to resort to actually drawing the lines, and applying primitives like graph intersection ( or solving some line intersection equation, which won’t take O(1)). This illustrates the weakness of today’s computers to learn concepts like shape perception. What then is the mechanism to build higher level concepts like “shape” representation in our digital systems? In the next sequence of posts, we will invent the answer. Meanwhile consider another case:
The importance of an object based frame of reference
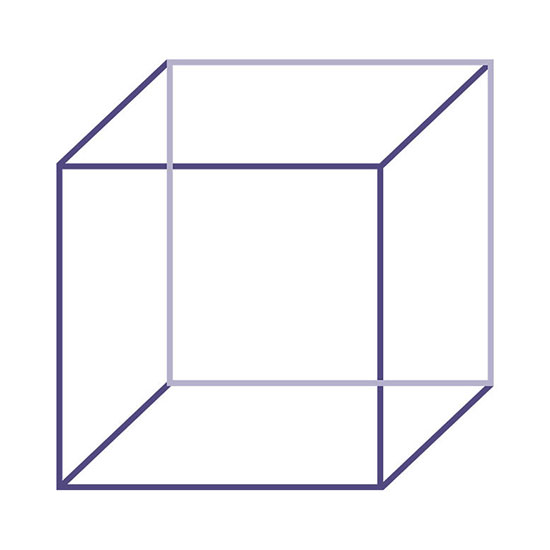
Consider a ‘cube’ resting with its front face in front of you. You are asked to mark it’s edges and vertices. How will we perform this task? We know that the face at the back mirrors the front face & they are connected by 4 edges. So whatever is the condition in the front face, will be same at the back. Therefore, we naturally mark the 4 points in the front face in our direct field of perception, and assume that the points at the back are similar. If there is a chance of compressing a 3-D object into 2-D representations (cube being explained by front facing face), our brains will manage to achieve this relaxation and reduce the feature set sizes to solve the shape task presented above.
But, does this implicit relaxation in shape representations always hold true in the viewer’s frame of reference. No.
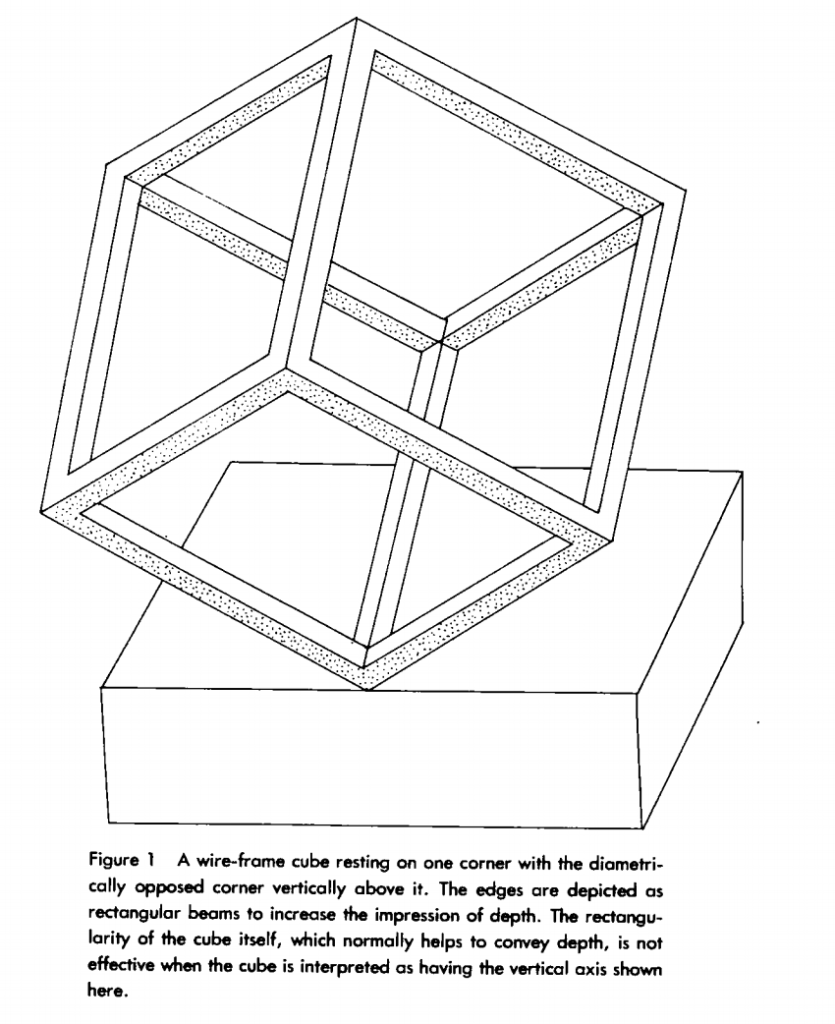
Instead of the front facing cube, now the entire cube is rotated by making the extreme opposite diagonal vertical. Can you still find the points? On first try, you will only locate 6 points instead of 8. The reason for this is that the diagonal along which the cube is made vertical, holds components along all the three coordinate directions. Therefore, there is no symmetry from the user’s frame of view.
But, now rotate your head to 45 degrees so that you visualize the straight cube again. You can solve the task efficiently again. However, this random rotation of our heads to perceive the shapes of the objects is not possible everytime. So what can we do ? We know that a front facing cube allows for relaxation…..We can assign two frames of reference, one being object based and one being viewer based. In the object based frame, the cube is always front facing. But in the viewer based frame, the object rotates in the real world. Don’t hurry up…. There are 2 points which we need to reiterate in the viewer based frame. Let’s take a step back.
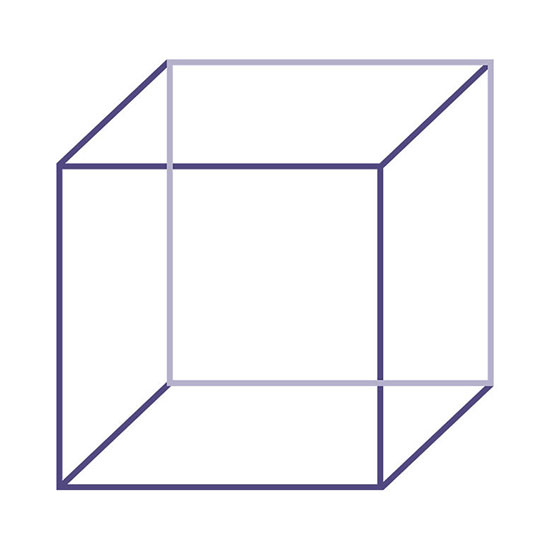
When the cube was in front of you, it’s object based frame and viewer frame co-incided with each other. Keeping this arrangement intact, rotate your head left/right. Does the shape/representation of the cube change? No. This means, that when we stand at a particular viewer position, the shape of the cube can be formed at different ‘retinal positions’. However, we still perceive those images as same. Hence:
- In case the viewer is at a location, the object based frame representations hold no correlation with the varying retinal representations.
There is one more degree of freedom possible in the viewer frame. Imagine that now the cube is fixed but you physically move in the 360 degree sphere surrounding it. Will you see different shape of the cube now? The answer is a resounding YES. This means that the object representations, are a function of the user spatial location but independent of the retinal representations.
One next obvious question is that how the human brains manage to represent these infinite viewer positions in a limited memory. Let’s think mathematically. The cube consists of edges with two types of relationships: a) the relationship between the edges b) the relationship of each edge with the viewer. Which of these two relationships depend on the viewer position?
Then answer is b). Therefore, we can drop the relationships between the edges, since the entire object is exposed to the viewer frame at the same time (more on this later). For now, each edge can be defined relatively i.e. it is behind some other edge, as a function of user location. There is one problem with this analogy. For each user location, we need to store the relationships of all the edges, which is gonna be memory intensive. These relationships vary continuously as the user changes his position. Is there a method of modelling this ‘continuous function’, instead of storing discrete function values as a dictionary of features at each location? (Think ‘patterns’, the answer lies in activation functions which change the strength of a pattern, but the underlying pattern (the particular neurons being activated) remains same representing a particular concept(variation of shape representation as a function of user spatial location)).
When do the relationship between the edges become important ?
There is one small change we make. Instead of the entire cube now, think that only a small portion of it is visible through a peephole. We no longer see all the edges of the cube from different viewpoints, because only limited portion of the cube is exposed by the peephole at a time. Therefore, we no longer can model the relationships of all the edges from the user viewpoint.
Devising the ‘retinal frame’ and ‘object based’ frames of reference.
We arrive at a grand interpretation. There is a ‘viewer’ based of reference, which consists of the images formed on the retina, and the nature of the object shape as a function of user location. This leads us to:
-
There exists a ‘viewer’ frame of reference. The patterns of the activity corresponding to the same user location, but different head orientations map to the same shape representations of an object.
-
There is an ‘Object based frame of reference’. The relation of the cube’s edges in that frame of reference remain same irrespective of the cube’s orientation in the user space.
We explained the variations of the cube’s perceived shape in the viewer. The absolute edge relationships of the object are taken care of in the Object frame. There is one thing still remaining. Remember how the peephole was able to expose the different parts of the cube to the outside world. The nature of the cube hadn’t changed. The user space was still a 360 degree trajectory around the peephole. Still when the object being exposed changes, the user perceives a different shape. This means, that there is something bridging this gap of object based frame , and the viewer frame.
- There is a third frame that maps the ‘patterns’ in the object based frame of reference to the ‘viewer’ based of reference.
Above three points lead us to the following structure of the proposed neural network:
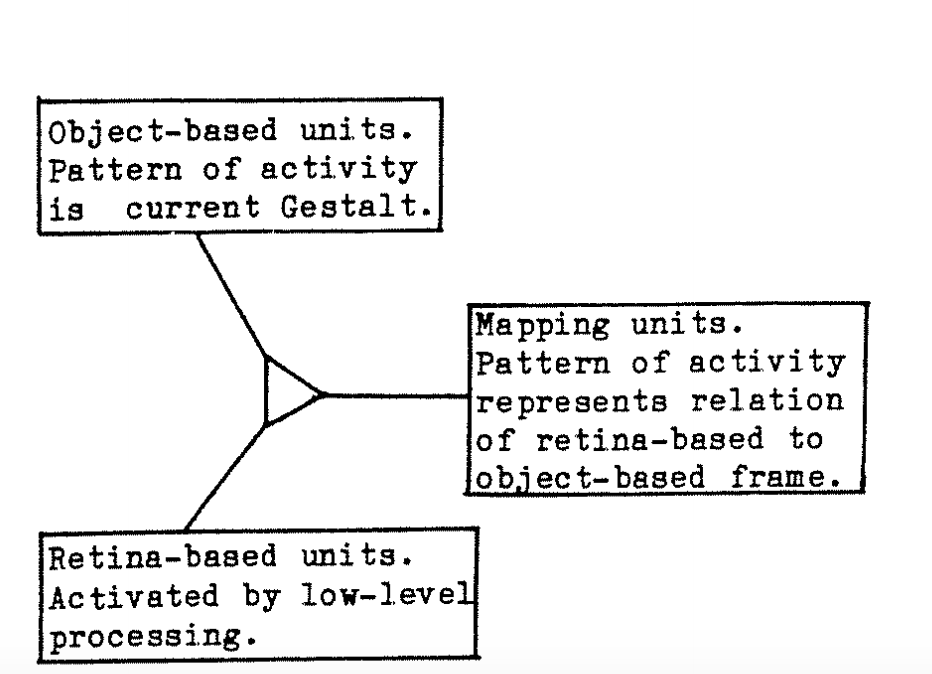
There is one thing that still troubles me. Suppose the neural network is made to output some pattern in the object frame of reference. How, the human perceives it is limited to the retina based representations. We have managed to decouple the human ambiguity from the real truth by constraining that randomness in the viewer frame of reference. Now, we are free to represent the true object shape in the object frame of reference. Somewhere above in the post, I had written that a neural network must have spatial memory with an attention span to learn the concepts like shape. This means that the object based frame of reference must have a block which models working memory that stores a sequence of excitation patterns in the network.
I still search for a way to model this spatial memory in object frame. As, we finish this post, we continue this blog’s tradition to end with a truth. A quote comes to our mind.
We are nothing but ants in the vast expanse of the cosmos, Our scientific theories are just observations that agree with our world, As we discover new worlds through the Hubble, Those truths will break, And as our egos shall crumble, We have to start anew again….
rajat