Models of Information Processing in Brain
The current state of the art in AI is focusing it’s efforts towards exploring singularity. A simple brute-force, or searching for the best set of neural architectures to solve a problem is not the answer. If we ever hope to design a general purpose AI, we have to delve deeper into what principles motivated the development of neural networks.
Why does a brute force approach fail if the problem is relaxed ?
Consider the following task which is very easy for a human to perform:
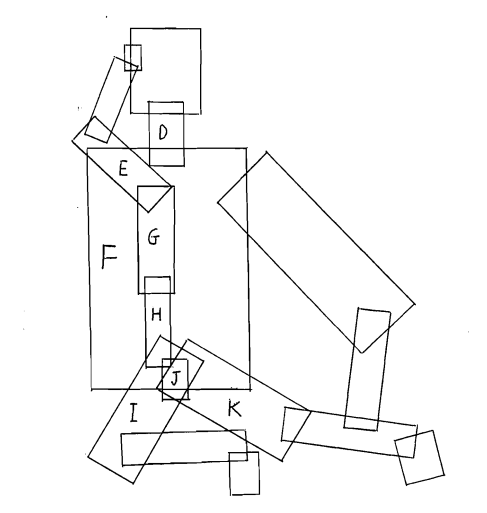
A set of overlapping rectangles is given, which are of different sizes and orientations. The task is to identify the best subsets of those polygons, which can form a complete human. A naive way to approach this problem is to take the combinations of all these rectangles, and arrive at the best solution. However, the complexity of this approach touches the polynomial bounds.
For the sake of the argument, let’s focus on how this approach might look like. We would start with a rectangle, and label it as a body part (say a thigh). Then, the task is to choose relevant candidates among the rectangles which intersect this body part(thigh). A thigh is typically attached to two body parts in a human, i.e. a knee & the waist. We continue this process, till the entire human space is explored over all the possible sets of the available rectangles.
Now, suppose we “relax” our argument, and allow that the human being might be missing some of the body parts. For example, he might be disabled and not possess a lower leg. Will our “exploratory brute-force heuristic” work in this case ? The answer is NO. Consider the case that we definitely know that one of the boxes represents the palm of a human hand. We need to discover, a subset of 5 intersecting boxes which represents the fingers. But, if there are only 4 boxes present (representing 4 fingers), will the algorithm select all 4 and detect that one of the fingers is missing ? Hence, for any generic brute-force heuristic, there are two sorts of decisions it must make at each body part:
- The best body part a particular rectangle represents.
- The amount of trade-off, i.e. the relaxation from a ideal human representation. (In the palm example, our algorithm had to relax the strict requirement for the five fingers, and settle down for 4).
There are 206 bones in a human body, and each one of them might have a different set of rules with each other. For each of the rectangle we explore, we might need to have a 206X206 matrix to represent the above rules properly. Now, imagine the computational complexity when such a system will actually brute-force over a possible set of rectangles to obtain the best global human representation!!!! This leads us to conclude, that a brute-force based approach is not the solution if relaxation is introduced into the problem.
To solve the problem of converging to the best possible global representation, we cannot hope to do best at each brute-force level. Suppose, we are given a rectangle which is modeled as a thigh. But, how do we know whether it is a left thigh or a right thigh of a human (since the immediately connected rectangles can only be the waist or a knee). In that case, we need to do the depth-first search again, which again increases the computational complexity. Consider the following diagram:
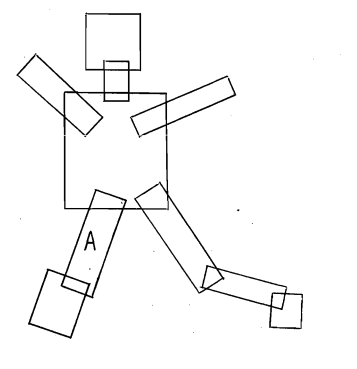
Suppose we are looking at the block A. It can be considered as a ‘calf’ since the box below it can represent the foot and the box above it can represent a knee joint. If, we zoom out then A can be easily seen as ‘high’ instead of the ‘calf’. The point to understand here is that the locally better alternative (i.e. calf) was not ultimately the best possible answer in a global representation (where it became thigh). This mechanism helps us to understand that human perception operates at two levels:
- A local level, where a representation might be relaxed in favor of a better global alternative.
- A global representational level, where the entire human torso can be visualized together.
It means that when we perceive an object as human, we tend to look at things from the global level, and some implicit relaxation occurs in our brains. However, our machines explore the brute-force space at the local level, at which the decisions need to be relaxed. Ok, now we have settled on the fact that the brute-force algorithms need to allow the relaxation at the local level, discover a global representation, and use that information to guide the local answers to correct global answers. But, there is a catch.
Our brute-force heuristic will spit out the “global candidate representation” only when it has finished its execution. How then, can we hope to understand the “amount of relaxation” needed at each level, if the global representation is learned at the end? This represents a “chicken in the egg” problem.
To get out of this huddle, we urge you to make an assumption. For a moment, assume that the global representation of the human puppet is observed in O(1). Will a baby, adult and old human arrive at the same representation irrespective of their medical knowledge, age, intellect, and maturity? No. But, there will be a certain set of global rules which the global representations of each of them will follow ( eg, a person has one neck only). This means, that global representations possess the following properties:
- They can be different according to who perceives them, but possess a common set of rules (local constraints) irrespective of what the current global representation might be.
- The correct global representation at any instant, provides the information to relax the local constraints in favor of the better global representation.
My last try to explain this analogy is to ask you to consider a drop of water flowing from the hill. The entire droplet mass can be visualized as a single droplet flowing along the pool’s center of mass[COM]. To enable this COM’s trajectory, each of the particular molecule representing that droplet makes a trade-off (relaxation of local constraints).
More formally, we assume the best global representation to be determined by a point in the higher dimensional vector space. A set of constraints is made to operate at each local location. Each such location possesses a certain set of constraints, which govern the axis of our higher dimensional plain. Then, the aim of such a device has to be to explore the set of points in the higher space, satisfying the locality constraints. This is the fundamental intuition behind relaxation.
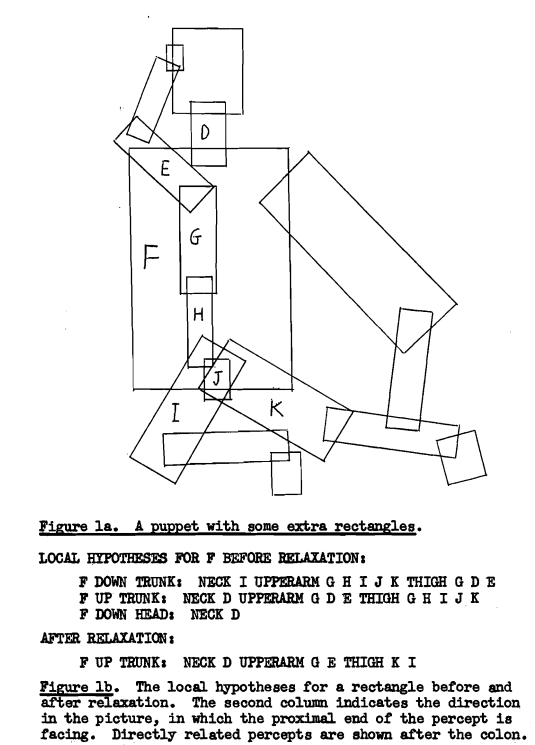
Relaxation manages to extract non-conflicting global representations much quicker than brute-force. But, we cannot rest here. Having thus discretized the levels at which perception occurs, we need to explore the mechanism via which this intuition can be built in the computing devices of today. That is our next order of business.
The mechanics of parallel operations in the brain
If the system needs to relax constraints at varying degrees of granularity, it must have a certain amount of parallel hardware built into it. Consider how a traditional central processor-based computer will solve the above problem. Each body part will be represented by a data structure, will be stored by an address in the disk. The CPU would retrieve those entities with ‘addresses’, process them, and make a decision about the global representations. The disadvantage of such an approach is that the central unit [CPU] has to wait till all the entities are fetched during the clock cycle ( assuming that the RAM does not get filled up first). How then can we hope to discover the global representation in 0(1) if the I/O bottlenecks us?
Critics might say that ‘relaxation’ might occur at a ‘data structure’ level. In other words, each location in the disk would store pointers to immediately connected body parts (Think of how a ‘tree’ is represented). Then, instead of bringing the entire body into the central processor for analysis, only a certain set of body parts would need to be fetched. The lazy fetching paradigm still contains its own intrinsic set of problems. Suppose, we eliminate the notion of a central processing unit in the favour of a distributed set of CPU’s for each body part. Still, the computer has to discover a set of rectangles in a serial manner (eg, for an arm, the arm joint will have a pointer to a hand, which in turn has a pointer to a finger). This limitation leads us to conclude that exploring the way of distributed computing, as an alternative to central processing is NOT the option for extracting the global representations of varying size objects in constant time.
Next, think about where does this disadvantage stems from? The reason for serially exploring the data structures at the granularity of each body part was that there was a memory bottleneck that limited only a single body part to be represented in each memory location. It was also assumed that each body part will be defined by an ‘address’. Unless, we know the address of a part, we cannot fetch it from the memory and establish a global identity. This makes us understand the following two phenomena:
- A future computing device consisting of a set of distributed processing units would not be able to establish a global identity in real-time since an address-based approach requires a set of body parts to be explored at each local level.
- There will be a plurality of processing units at each local level, with each unit being assigned a subset of human space to be explored serially. If the size of this subset differs for each CPU, then some of the CPUs will be ideal while other ones finish their exploration phase. Hence, we need a message-passing scheme, so that a CPU can contribute to the exploration phase of another CPU if its own exploration is completed. Only, then can we benefit from the true power of parallelizability.
This device is called as a Vonn Neumann Machine. Although the idea is old, it consists of a central processor which operates sequentially on the memory locations represented by an address. If a data structure is stored as parts in various locations, it takes linear time to process it till the entire data structure in explored. But, when a human sees a data structure(think for example, if we see a big human or a small human, our brains take a constant amount of time). This means that we need to design something where the exploration phase takes constant time, irrespective of the data structure size. Naturally the basic approach of “addressing” the memory is thrown out of the window and again puts us in a state of confusion.
What then is the way to represent patterns in computing machines? The answer lies in the distributed machinery, but without the headaches of local processors. Take the example of a group of children ‘cheating’ together on a sequence of questions. Although each of the child possesses a different bias about what the correct answer might be, the group needs to reach a consensus at which all the children will mark the same answer together. We need to understand that:
The number of children remains same even though they may be asked new questions every time. The group as a whole, becomes capable of answering each question efficiently. In other words, the scale of our input data (no of questions we ask) holds NO adverse impact on how the group of children can answer the questions efficiently (each that each child possesses a certain minimum intelligence level, and contributes to the group).
This grand design means that there is a certain amount of intelligence which can be achieved at the level of a ‘group’, without actually storing each data structure as a part of the memory. Instead of the memory addressing scheme, the basic unit of representation becomes the “pattern of stimulus” which such a system is exhibited to. (The nature of the questions we ask will govern which particular child contributes more to the overall group, and guides it’s centre of mass). How can this “pattern scheme” be devised into our machinery?
A black box view of our machinery yields it’s properties:
- It possesses a multiple set of ‘individuals’ who work as a group towards a common task. Each individual possesses a certain ‘set of expertise’ and contributes something to the group.
- The amount of the contribution which each such entity makes depends on whether the external task they perform correlates with their expertise.
- A same set of ‘individuals’ is subjected to a continuous stream of external stimuli. Inspite of that, they should be able to perform the task at the same or better level of performance.
This is the basic crux of learning algorithms.
What then remains is a mathematical formulation of such a system, and proving point [3]. i.e. it can achieve an improved level of performance inspite of being subjected to too many external stimuli. (no of questions we ask in the “cheating students example”).
Realising our dream with the McCulloch-Pitts Neuron
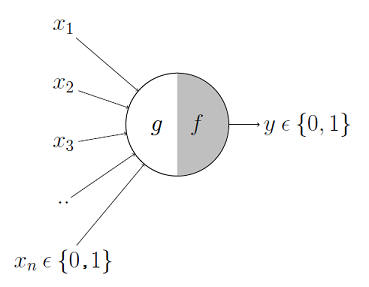
As we mentioned above, there is a certain set of individuals which need to be subjected to continuous external stimuli. This is easily approximated by the perceptron model.
Think of a perceptron as a very small learning machine. It has to make a decision to respond to an external stimulus by either activating itself or remaining in a de-activated state. It interacts with others, by a synaptic connection. The ‘strength’ of this connection will be governed by a set of weights. Then, such a basic entity has to make a decision “when actually does it respond”. This is given by a threshold T. In short the perceptron can be worked as follows:
- It is subjected to an external stimuli, which is approximated by numbers. It produces an output. This output is compared to a threshold T. Based on this, the perceptron decides whether it should interact with others.
- The strength of interaction with others is determined by a set of weights it possesses.
A group of such perceptrons taken together will produce a “pattern” of responses for an external stimuli. Now, we have to realise something. Suppose an external stimuli S gives a pattern P. Then, the same set of perceptrons are subjected to some other stimulus. If, we give the same external stimuli S again, then the system should produce the same pattern P again. Only then can such a system be said to possess a “memory” and be considered as an alternative to the traditional Vonn Neumann Machine. When we derive this mathematically, we find that the input stimuli must be orthogonal for memory reconstruction by the neural machine. I am not gonna prove this to avoid boring you with gory details.
The limitations of the perceptrons which seems to have been carried out in the neural architectures today
The “better” we try to understand the intuition behind the design of the current neural architectures, the more troubled we become. There are certain points:
- Consider a single perceptron which is trying to learn an optimal threshold T at which it should respond. However, if all it sees is the positive samples, there are no updates being made. Therefore, there is no “learning” which occurs if the system keeps on performing well. This is not how we learn in our real life. If our work yields positive results, we learn better. This can be a good architectural exploration.
- Another problem appears when multiple of such “perceptrons” are considered to be a part of various neural network layers. How do we decide which of the layer’s weights must be updated during the backpropogation? Although, the global back prop algorithm updates the layers according the individual ‘layer wise’ learning rates, it remains a fundamental design question.
We believe that the answer to this question lies in the fact that the “patterns” of responses of ‘neurons’ are not representative of their internal states. Don’t worry if you can’t understand this now, we would explain in a later post.
The End….
We hope this post helped you understand the intuition behind today’s neural networks. A lot has been achieved, but an even greater journey lies ahead of us. It is the great people like you, who contribute to the thriving research community. We end by remembering the way Einstein concludes his ETH Zurich’s “ Brownian Motion” paper.
Should the scientists of tomorrow try to verify the claims that we make today, they will realise that those are a part of the greater truth. The God does not play Dice, so all the man can do is realise how the Dice rolls and pray that the things fall into their natural order. - Albert Einstein.
rajat